AutoRec - Autoencoders meet collaborative filtering
Sedhain, Suvash, et al. “Autorec: Autoencoders meet collaborative filtering.” Proceedings of the 24th international conference on World Wide Web. 2015.
추천 시스템을 공부하고 개발한 지는 꽤 되었는데 생각보다 공부한 내용들을 제대로 정리한 적이 없다는 것을 깨달았습니다. 이제서야 예전에 읽었던 논문들도 다시 정리해야겠다는 생각을 하게 되었는데요. 페이스북 RS-KR 그룹을 살펴보던 중 16년도부터 읽어볼만한 논문들을 정리한 목록을 보게 되었습니다. 그래서 해당 논문들을 통해 추천 시스템이 어떻게 변화했는지 흐름을 살펴보고 PyTorch로 직접 구현해보고자 합니다.
AutoRec
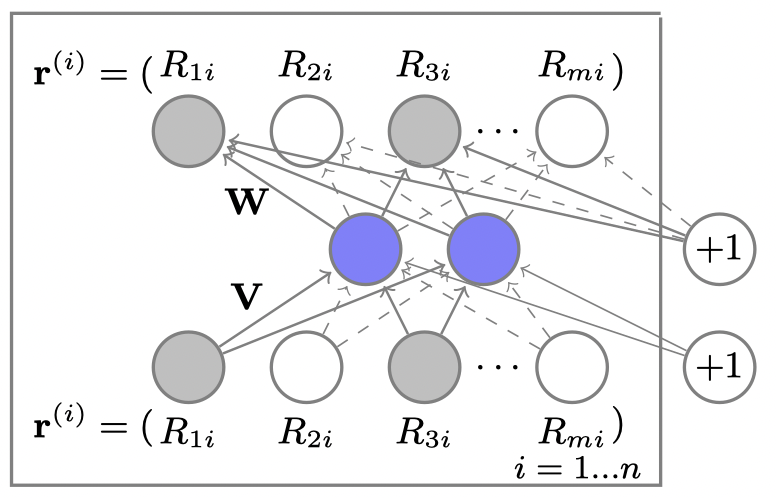
우선 본 논문에서는 Item-based AutoRec이 가장 높은 성능을 보인다고 언급하기 때문에 모두 아이템 관점에서 설명하겠습니다. 평점 기반의 협업 필터링에서 사용하는 사용자-아이템 평점 행렬을 생각해봅시다. 해당 행렬을 Autoencoder로 복원한다고 했을 때 평점 벡터 입력값을 $\mathbf{r} \in \mathbb{R}^d$이라고 했을 때 이를 복원하는 $h(\mathbf{r}; \theta)$를 다음과 같이 정의할 수 있습니다.
\[h(\mathbf{r}; \theta) = f(\mathbf{W} \cdot g(\mathbf{Vr} + \boldsymbol{\mu}) + \mathbf{b})\]여기에서 $f(\cdot)$와 $g(\cdot)$은 모두 활성화 함수 (activation function)이며, $\theta = { \mathbf{W}, \mathbf{V}, \boldsymbol{\mu}, \mathbf{b} }$ 입니다. 각각의 파라미터가 가리키는 내용은 Figure 1을 통해 확인할 수 있습니다. 활성화 함수의 경우 저자가 identity function과 sigmoid function을 모두 실험해본 결과 encoder에서는 sigmoid를, decoder에서는 identity function을 사용했을 때가 가장 좋은 성능을 보였다고 합니다. 개인적으로는 encoder와 decoder에 모두 sigmoid를 사용했을 때 성능이 좋지 않을까 했는데, 실제 결과에 큰 차이가 없는 것을 보면 sigmoid를 사용해도 무방할 것 같습니다.
여기까지 정의하였다면 Autoencoder는 실제 평점 벡터 입력값과 복원값 사이의 차이를 줄이도록 학습을 하게 됩니다.
\[\min_\theta \sum_\mathbf{r} \| \mathbf{r} - h(\mathbf{r}; \theta) \|^2_2\]그래서 item-based AutoRec은 다음의 regularized objective function을 사용합니다. 이 때 objective function 계산에서는 실제 관측된 평점 값만을 고려합니다.
\[\min_\theta \sum^n_{i=1} \| \mathbf{r}^{(i)} - h(\mathbf{r}^{(i)}; \theta) \|^2_\mathcal{O} + \frac{\lambda}{2} \left( \| \mathbf{W}_F^2 \| + \| \mathbf{V} \|^2_F \right).\]Implementation
AutoRec PyTorch 구현체는 제 깃허브 저장소에 올려놓았습니다.
https://github.com/otzslayer/torch-autorec
GPU로 학습하게 해놓았고, ./config/config.yaml에 하이퍼파라미터 등 설정값을 저장해놓았습니다. 논문과 동일하게 RMSE 값을 확인했고, 실제 논문처럼 5-fold CV를 수행해서 결과를 확인하진 않았습니다.
그나마 신경쓴 부분이라고 한다면 논문에도 나와있지만 Loss를 계산할 때 학습 데이터에서 원래 있었던 값들만 마스킹(masking)해서 사용한 부분입니다. 궁금해서 마스킹을 빼고 Loss를 계산해보니 확실히 값이 형편없긴 하더라구요.
1
loss = loss_f(reconstruction * input_mask, input_vec * input_mask)
그리고 논문에서는 L2 regularization을 사용하지만 실제로 모델의 학습 성능을 높이는 것 같지는 않았습니다. 이 부분은 조금 더 확인을 해봐야겠지만 우선은 모델 설정값에서 L2 regularzation을 0으로 설정해놓았습니다.
마무리하며…
사실 요즘의 환경에서는 거의 쓰기 어려운 모델이라고 생각합니다. 대부분의 학습 데이터는 implicit feedback이고 여기에 추가적인 메타 정보들을 추가하여 모델링을 진행하게 되니까요. 하지만 처음으로 Autoencoder를 협업 필터링에 적용한 논문인만큼 읽어볼 가치는 있다고 생각합니다. 적당히 RBM 관련 내용이나 마음에 걸리는 몇몇 부분들을 제외한 채 금방 읽어보기엔 충분하다고 봅니다.