Great Expectations을 이용한 데이터 파이프라인 검증
0. 들어가며
0.1 Motivation

분석 프로젝트를 수행하게 되면 여러 문제를 직면하게 됩니다. 모델을 학습하기 위한 자원이 충분하지 않다거나 결과가 생각처럼 좋지 않다거나 말이죠. 하지만 이런 문제들은 데이터에 대한 충분한 이해와 충분한 시간을 들여서 모델을 운영 환경에 이관하기 전에 해결이 가능합니다.
하지만 운영 이관 후에 발생하는 문제는 위 상황보다 조금 까다로울 수 있습니다. 갑자기 모델의 성능이 이전만 못해진다든지, 잘 돌던 배치 작업이 수행되지 않는 경우도 발생하고요. 오랜 경험은 아니지만 이런 문제는 모두 데이터에서 발생합니다. 데이터의 분포가 갑작스럽게 변하는 Dataset shift가 발생할 수도 있고, 원인 미상의 문제로 특정 컬럼이나 전체 데이터가 아예 들어오지 않는 경우가 생깁니다.
우리 분석가들은 이런 경우에 많은 공수를 들여 문제를 해결하고자 합니다. 해결하는 중에 ‘다음에는 이런 문제가 발생하더라도 해결할 수 있게 검증할 수 있는 방법을 고민해야겠다.’라고 생각하지만, 다음 프로젝트 투입 일정에 치여 결국 문제를 손수 한 땀 한 땀 해결한 채 손을 놓게 됩니다. 당장 저도 퇴직 예측을 운영하면서 이런 문제가 수없이 발생했지만 결국 매월 1회 배치라는 이유로 그때마다 해결했었습니다.
하지만 ML 모델을 운영하는 것이 중요해지는 때에 이런 문제를 해결할 방법이 없을까 찾던 중 Great Expectations 이라는 데이터 파이프라인 검증 오픈소스를 찾게 되었습니다. 여러 데이터 소스에 대해 사용할 수 있고, 데이터 검증 뿐만 아니라 문서화와 프로파일링까지 깔끔하게 할 수 있는 툴로 우리 분석가들이 프로젝트에서 이 툴을 어떻게 활용할 수 있을까 고민해보았습니다. 본 포스트에서는 Great Expectations의 설치부터 실제 활용 시나리오까지 다루고자 합니다. 가장 많이 사용하는 데이터 소스인 Pandas 데이터 프레임에 대해 Expectations을 만들고 검증하는 것까지 일련의 과정을 다루고, 추가로 다른 데이터 소스와 연결하여 사용하는 법을 다루고자 합니다.
0.2 Great Expectations의 특장점
- 데이터에 대한 일련의 테스트를 자동으로 생성함
- 항상 데이터에 대해서 테스트 코드를 작성하는 것은 매우 번거로운 일입니다. Great Expectations는 데이터를 프로파일링하여 자동으로 테스트를 수행합니다.
- Notebook 환경에서 쉽게 사용 가능
- 데이터 프로파일링과 데이터에 대한 여러 가지 설정을 Notebook 환경에서 쉽게 수행할 수 있도록 지원합니다.
- 깔끔한 문서화
- 데이터에 대한 프로파일링, 검증 결과를 하나의 문서로 깔끔하게 정리해줍니다.
- 여러 툴과 통합 가능
- Pandas, Spark, BigQuery, Databricks, MySQL, AWS Redshift, AWS S3, Apache Airflow 등 다양한 데이터 사이언스 툴과 통합이 가능합니다.
1. 준비하기
1.1 Great Expectations 설치
Great Expectations는 2022년 4월 기준 0.15.0 버전이 최신이며 Python 3.7 이상에서 사용할 수 있습니다. Pandas 최신 버전의 경우 Python 3.8부터 지원하기 때문에 되도록 Python 3.8 이상 버전 사용을 권장합니다. 설치는 pip를 이용해 간단하게 진행할 수 있습니다.
1
pip install great_expectations
설치가 올바르게 되었는지 확인하려면 다음의 명령어로 버전을 확인합니다.
1
great_expectations --version
다음과 같은 메시지가 출력되면 정상 설치가 된 것입니다.
1
great_expectations, version 0.15.0
1.2 Data Context 생성
Great Expectations에서는 프로젝트 구성 및 설정을 Data Context를 이용해 관리합니다. 프로젝트 내용이 담긴 루트 디렉토리에서 다음의 명령어를 실행합니다.
1
great_expectations init
그러면 다음의 메시지가 출력됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Using v3 (Batch Request) API
___ _ ___ _ _ _
/ __|_ _ ___ __ _| |_ | __|_ ___ __ ___ __| |_ __ _| |_(_)___ _ _ ___
| (_ | '_/ -_) _` | _| | _|\ \ / '_ \/ -_) _| _/ _` | _| / _ \ ' \(_-<
\___|_| \___\__,_|\__| |___/_\_\ .__/\___\__|\__\__,_|\__|_\___/_||_/__/
|_|
~ Always know what to expect from your data ~
Let's create a new Data Context to hold your project configuration.
Great Expectations will create a new directory with the following structure:
great_expectations
|-- great_expectations.yml
|-- expectations
|-- checkpoints
|-- plugins
|-- .gitignore
|-- uncommitted
|-- config_variables.yml
|-- data_docs
|-- validations
OK to proceed? [Y/n]:
Y를 입력해서 Data Context 생성을 마무리하시면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Congratulations! You are now ready to customize your Great Expectations configuration.
You can customize your configuration in many ways. Here are some examples:
Use the CLI to:
- Run `great_expectations datasource new` to connect to your data.
- Run `great_expectations checkpoint new <checkpoint_name>` to bundle data with Expectation Suite(s) in a Checkpoint for later re-validation.
- Run `great_expectations suite --help` to create, edit, list, profile Expectation Suites.
- Run `great_expectations docs --help` to build and manage Data Docs sites.
Edit your configuration in great_expectations.yml to:
- Move Stores to the cloud
- Add Slack notifications, PagerDuty alerts, etc.
- Customize your Data Docs
Please see our documentation for more configuration options!
Data Context를 생성한 후 디렉토리의 구성은 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
.
├── data
│ ├── yellow_tripdata_2019-01.csv
│ └── yellow_tripdata_2019-02.csv
└── great_expectations
├── checkpoints
├── expectations
├── plugins
│ └── custom_data_docs
│ ├── renderers
│ ├── styles
│ │ └── data_docs_custom_styles.css
│ └── views
├── profilers
├── uncommitted
│ ├── data_docs
│ ├── validations
│ └── config_variables.yml
└── great_expectations.yml
디렉토리 구조에서 각각은 다음을 의미합니다.
great_expectations.yml파일은 배포 파일들의 주요 설정을 포함하고 있습니다.expectations폴더에는 데이터에 대한 모든 Expectations을 JSON으로 변환한 파일들이 저장됩니다. 이 JSON 파일들은 다른 폴더에 저장할 수도 있습니다.plugins/폴더는 사용자가 직접 개발한 커스텀 플러그인을 저장합니다.uncommitted/폴더는.gitignore과 유사한 역할을 합니다. 실제 버전 관리에 포함되지 않는 파일들을 저장합니다.uncommitted/config_variables.yml파일은 데이터베이스 비밀번호와 같은 민감한 정보들을 포함합니다.uncommitted/data_docs는 Expectations, 검증 결과, 기타 메타데이터에서 생성된 데이터 문서들을 포함합니다.uncommitted/validations는 Great Expectations로부터 생성된 검증 결과를 포함합니다.
1.3 예제 데이터
본 포스트에서 사용하는 데이터는 NYC 택시 데이터입니다. 뉴욕시에서 공개한 데이터셋으로 매달 업데이트가 된다는 특징이 있습니다. 데이터는 택시 탑승 위치, 하차 위치, 지출 금액, 승객 수 등에 대한 정보를 포함하고 있습니다. 본 포스트에서는 학습 시 데이터와 운영 시 데이터가 다른 상황에서 어떤 결과가 나오는지에 관해 설명하기 때문에 다음의 두 데이터 샘플을 사용합니다.
yellow_tripdata_sample_2019-01.csv: 2019년 1월 데이터yellow_tripdata_sample_2019-02.csv: 2019년 2월 데이터
2019년 1월 데이터를 학습 시 사용하는 데이터, 2019년 2월 데이터를 운영할 때 사용하는 데이터로 가정합니다. 2019년 1월 데이터로 Great Expectations을 사용해 각 데이터 컬럼에 대한 Expectations을 생성하고 2월 데이터에 대해서 어떤 문제들을 검출하고 모니터링하는지 알아볼 예정입니다.
해당 데이터 파일은 위처럼 data 폴더 내에 다운로드하여 사용합니다.
2. 데이터 연결하기
이제 위에서 생성한 Data Context를 데이터와 연결해야 합니다. Great Expectations에서는 이 연결할 데이터를 Datasources라고 부릅니다. Great Expectation은 다양한 Datasource와 연결이 가능합니다.
- Pandas
- Spark
- RDBMS (Postgres, MySQL, MSSQL)
- Cloud Services (Databricks, AWS Redshift, AWS S3, BigQuery)
우선 분석가들이 가장 많이 사용하는 Pandas 데이터 프레임과 연결하는 법을 알아본 후 다른 Datasource와 연결하는 법에 대해서 알아보도록 하겠습니다.
2.1 Pandas 데이터 프레임과 연결하기
처음 Data Context를 만들었던 디렉토리에서 터미널을 통해 다음 명령어를 실행합니다.
1
great_expectations datasource new
그러면 다음과 같은 문구가 출력됩니다.
1
2
3
4
5
6
Using v3 (Batch Request) API
What data would you like Great Expectations to connect to?
1. Files on a filesystem (for processing with Pandas or Spark)
2. Relational database (SQL)
: 1
Pandas나 Spark를 쓰면 1, 다른 관계형 데이터베이스를 사용한다면 2를 입력하면 됩니다. 여기에선 Pandas를 사용하기 때문에 1을 입력하니다. 다음 문구가 출력되는데, 이 때도 Pandas를 선택하면 됩니다.
1
2
3
4
What are you processing your files with?
1. Pandas
2. PySpark
: 1
마지막으로 데이터의 위치를 입력하면 끝납니다. 상대 경로와 절대 경로 중 어떤 것을 입력해도 상관 없습니다.
1
2
Enter the path of the root directory where the data files are stored. If files are on local disk enter a path relative to your current working directory or an absolute path.
: data
여기까지 진행하셨다면 Datasource 설정을 마무리하기 위한 Jupyter Notebook 창이 열립니다. 따라서 Jupyter Notebook이 없는 환경이라면 반드시 설치를 하셔야 합니다.
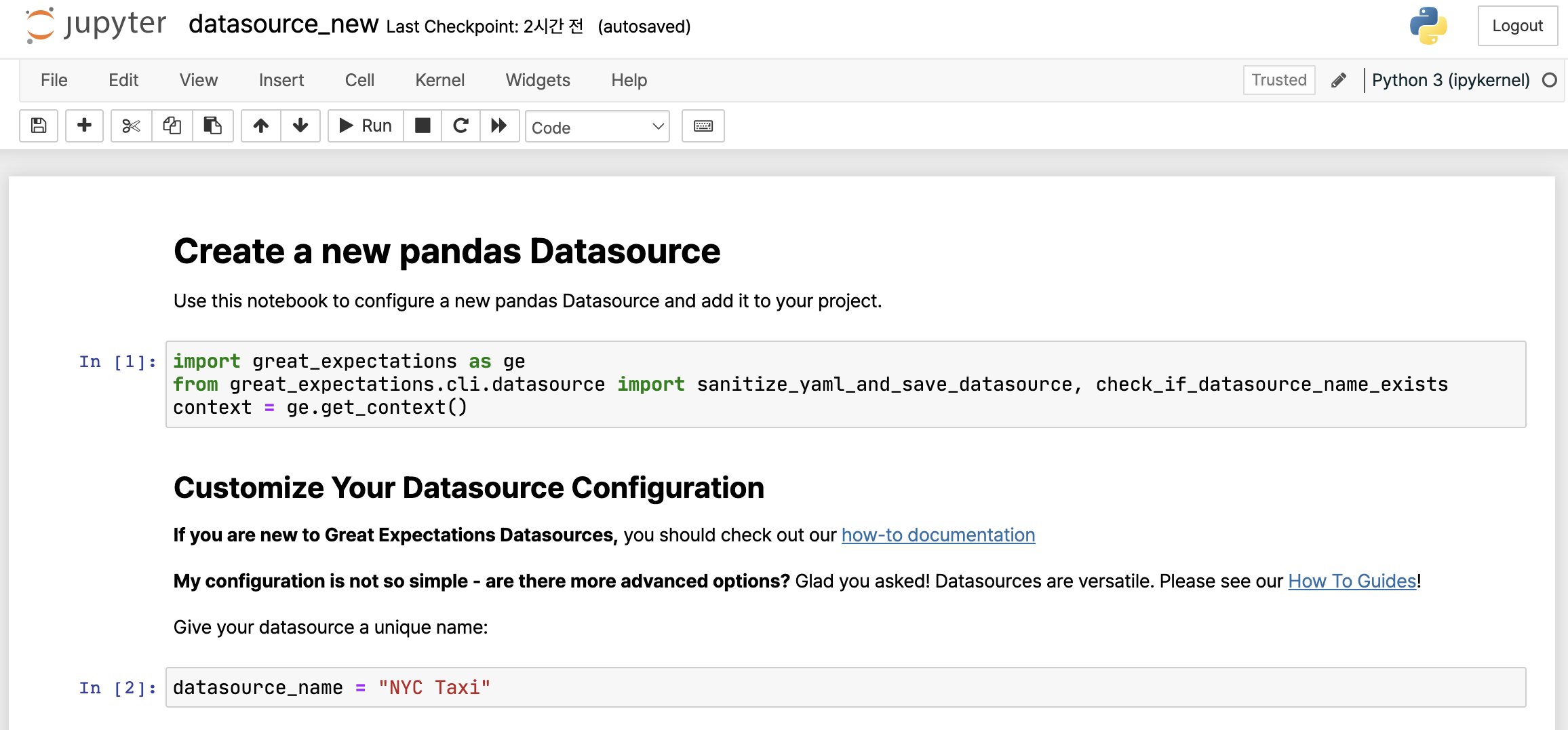
위처럼 Notebook 파일이 열렸다면 두 번째 셀에서 datasource_name을 수정합니다. 원하는 이름으로 바꾸면 되는데 저는 NYC Taxi로 설정했습니다. 이제 처음 셀부터 차례대로 모든 셀을 실행하여 오류가 발생하지 않았다면 Datasource에 대한 설정은 끝났다고 할 수 있습니다.
2.2 Datasources 설정 자세히 살펴보기
Jupyter Notebook을 통해 Datasource에 대한 설정을 진행할 때 가장 중요한 셀은 바로 세 번쨰 셀입니다. 해당 셀은 Datasource에 대한 직접적인 설정 내용을 YAML 포맷으로 저장하는 내용을 담고 있는데요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
name: NYC Taxi
class_name: Datasource
execution_engine:
class_name: PandasExecutionEngine
data_connectors:
default_inferred_data_connector_name:
class_name: InferredAssetFilesystemDataConnector
base_directory: ../data
default_regex:
group_names:
- data_asset_name
pattern: (.*)
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
batch_identifiers:
- default_identifier_name
Datasource마다 바뀌는 부분은 크게 execution_engine과 data_connectors 입니다.
execution_engine- Execution Engine은 불러들일 데이터와 검증할 데이터에 사용할 컴퓨팅 자원을 의미합니다.
PandasExecutionEngine,SparkDFExecutionEngine,SqlAlchemyExecutionEngine등이 있습니다.
- Execution Engine은 불러들일 데이터와 검증할 데이터에 사용할 컴퓨팅 자원을 의미합니다.
data_connectors- Data Connectors는 파일 시스템, 데이터베이스, 클라우드 저장소 등 외부 데이터 저장소에 액세스하는 일을 도와주는 요소입니다. 위 설정처럼 파일 시스템 내에 Pandas 데이터 프레임에 액세스하기 위해서
InferredAssetFileSystemDataConnector라는 클래스의 Data connector를 사용하기도 하고, 데이터베이스에 액세스할 때는InferredAssetSqlDataConnector같은 것을 사용하기도 합니다.
- Data Connectors는 파일 시스템, 데이터베이스, 클라우드 저장소 등 외부 데이터 저장소에 액세스하는 일을 도와주는 요소입니다. 위 설정처럼 파일 시스템 내에 Pandas 데이터 프레임에 액세스하기 위해서
이런 설정값은 Jupyter Notebook을 매번 실행할 필요 없이 ./great_expectations/great_expectations.yml 파일에서 수정할 수 있습니다.
3. Expectation 생성
3.1 최초 Expectation Suite 생성
데이터 연결이 끝났다면 데이터에 대한 Expectation Suite를 생성해야 합니다. Expectations란 “데이터에 대해 검증 가능한 가정들 (A verifiable assertion about data)”입니다. 특정 컬럼의 값 범위가 주어진 조건에 맞는지, 특정 컬럼에 결측값이 존재하는지 등 데이터에 대한 검증 가능한 테스트들이라고 생각하시면 됩니다.
우선 터미널에서 다음 명령어를 실행합니다.
1
great_expectations suite new
그러면 다음 메시지가 출력됩니다. 본 포스트에서는 Profiler를 이용해 자동으로 Expectation Suite를 생성합니다.
1
2
3
4
5
How would you like to create your Expectation Suite?
1. Manually, without interacting with a sample batch of data (default)
2. Interactively, with a sample batch of data
3. Automatically, using a profiler
: 3
그 후 아까 연결한 Datasource에서 사용 가능한 데이터를 인식하여 선택하도록 메시지가 출력됩니다. 첫 번째 데이터를 선택합니다. 위에서 언급한 것처럼 2019년 1월 데이터를 프로파일링에 사용하고 2019년 2월 데이터를 검증에 사용합니다.
1
2
3
4
5
6
7
8
9
A batch of data is required to edit the suite - let's help you to specify it.
Which data asset (accessible by data connector "default_inferred_data_connector_name") would you like to use?
1. yellow_tripdata_2019-01.csv
2. yellow_tripdata_2019-02.csv
Type [n] to see the next page or [p] for the previous. When you're ready to select an asset, enter the index.
: 1
여기까지 진행이 되었다면 새로운 Expectation Suite의 이름을 작성하시면 됩니다. 본 포스트에서는 ge_guide.demo로 하겠습니다.
1
Name the new Expectation Suite [yellow_tripdata_2019-01.csv.warning]: ge_guide.demo
그러면 Jupyter Notebook이 실행된다는 메시지와 함께 Expectation Suite를 생성하는 프로세스를 마무리합니다.
1
2
3
4
5
6
7
8
Great Expectations will create a notebook, containing code cells that select from available columns in your dataset and
generate expectations about them to demonstrate some examples of assertions you can make about your data.
When you run this notebook, Great Expectations will store these expectations in a new Expectation Suite "ge_guide.demo" here:
<Path of your project folder>/great_expectations/expectations/ge_guide/demo.json
Would you like to proceed? [Y/n]: Y
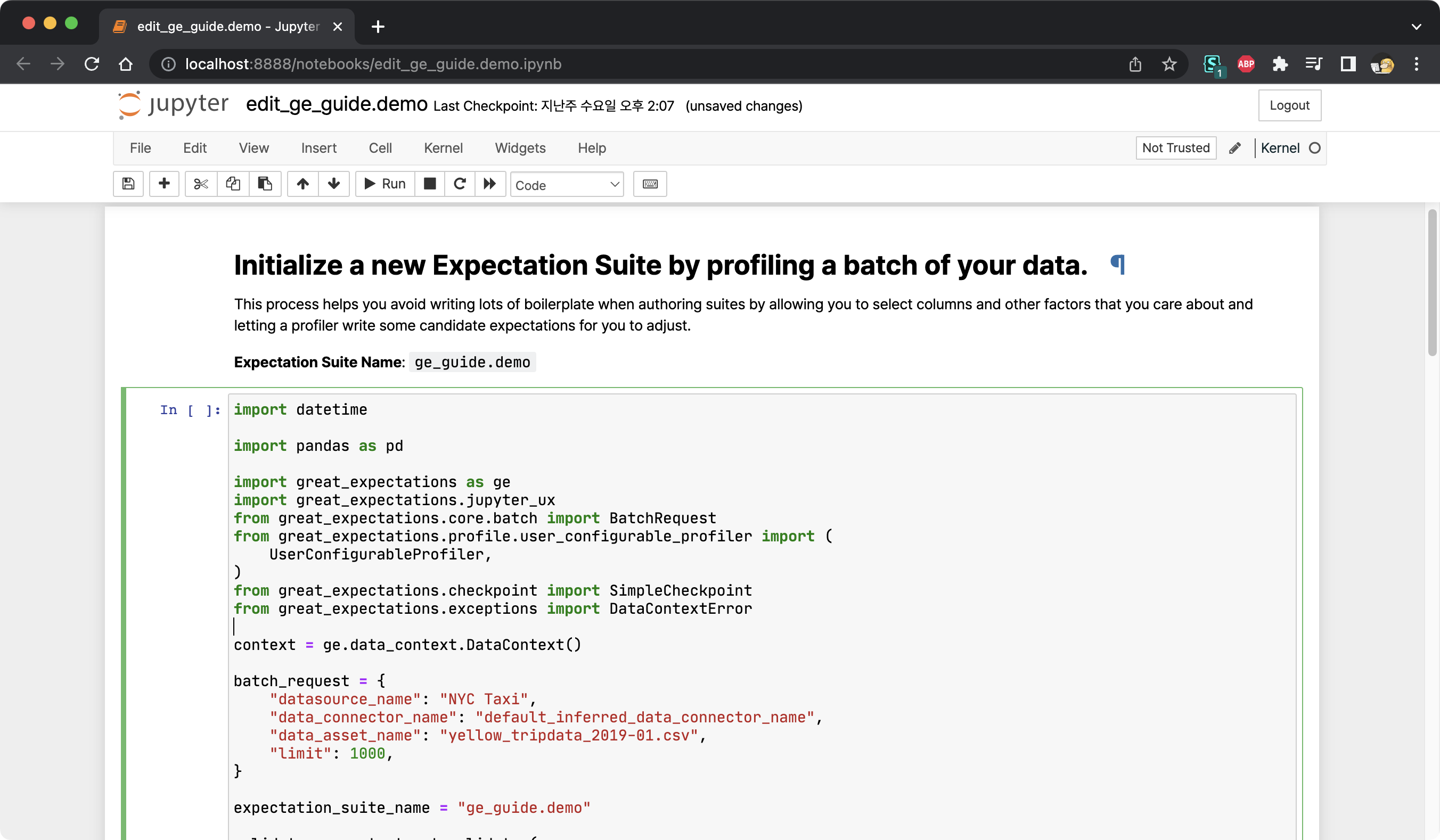
3.2 Expectation Suite 초기화
이제 데이터를 프로파일링하여 생성한 Expectation Suite를 초기화하는 작업이 필요합니다. 본 섹션에서는 실행된 Notebook 파일의 구성을 살펴보고 마지막으로 생성한 데이터 문서 (Data Docs)를 살펴보도록 하겠습니다.
Expectation Suite를 생성하여 실행되는 Notebook 파일은 총 네 개의 코드 셀로 구성이 되어 있습니다. 첫 번째 셀은 관련한 라이브러리를 임포트하고, Data Context를 불러온 다음 데이터 검증을 위한 Validator를 생성하는 내용을 포함하고 있습니다.

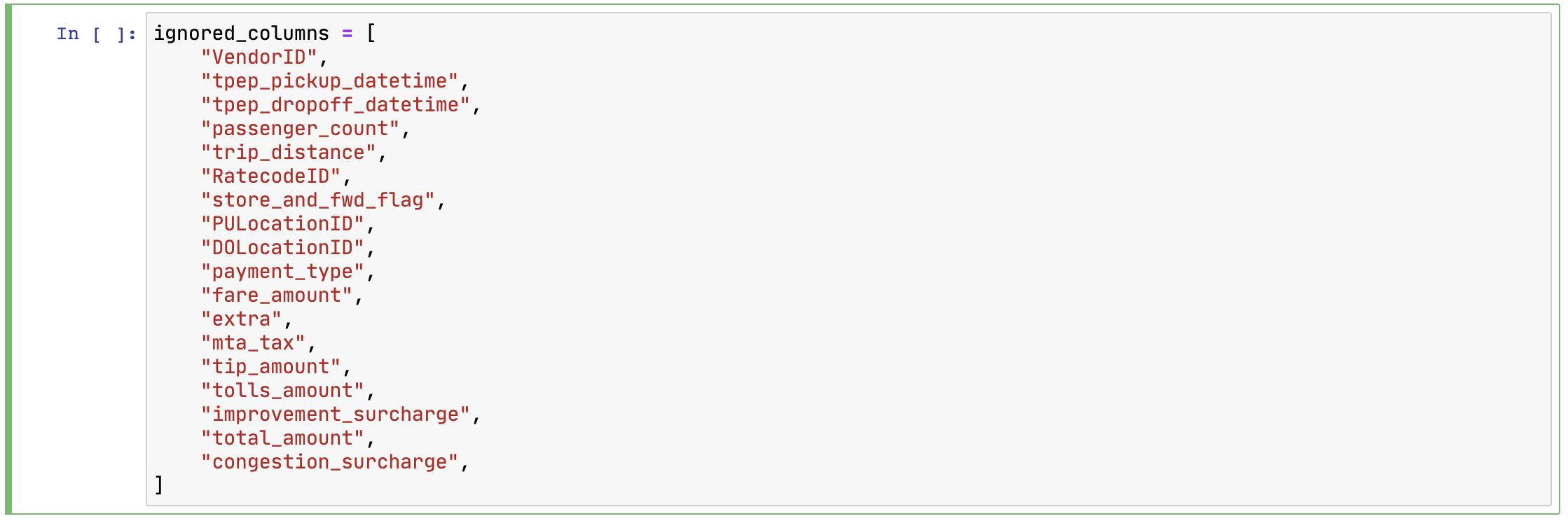
두 번째 셀은 데이터를 프로파일링할 때 무시할 컬럼들의 목록을 포함하고 있습니다. 기존 Notebook 파일에는 전체 컬럼으로 되어 있는데 필요에 따라 프로파일링할 컬럼들을 주석 처리하면 됩니다. 본 포스트에서는 컬럼들 중 "passenger_count",trip_distance","payment_type","fare_amount"를 주석 처리해줍니다.
세 번째 셀은 사용자 설정 프로파일러 설정을 할 수 있습니다. 처음 프로파일러를 생성할 때는 별도로 설정할 값은 없습니다.

마지막 네 번째 셀은 Expectation Suite를 디스크에 저장하고 불러온 데이터 배치에 대해 검증을 수행합니다. 그리고 데이터 문서를 실행시켜 주는데 여기서 검증 결과를 확인할 수 있습니다. 이 셀을 실행하면 지금까지의 설정을 바탕으로 작성된 데이터 문서를 확인할 수 있습니다.

데이터 문서는 다음과 같이 생겼습니다.
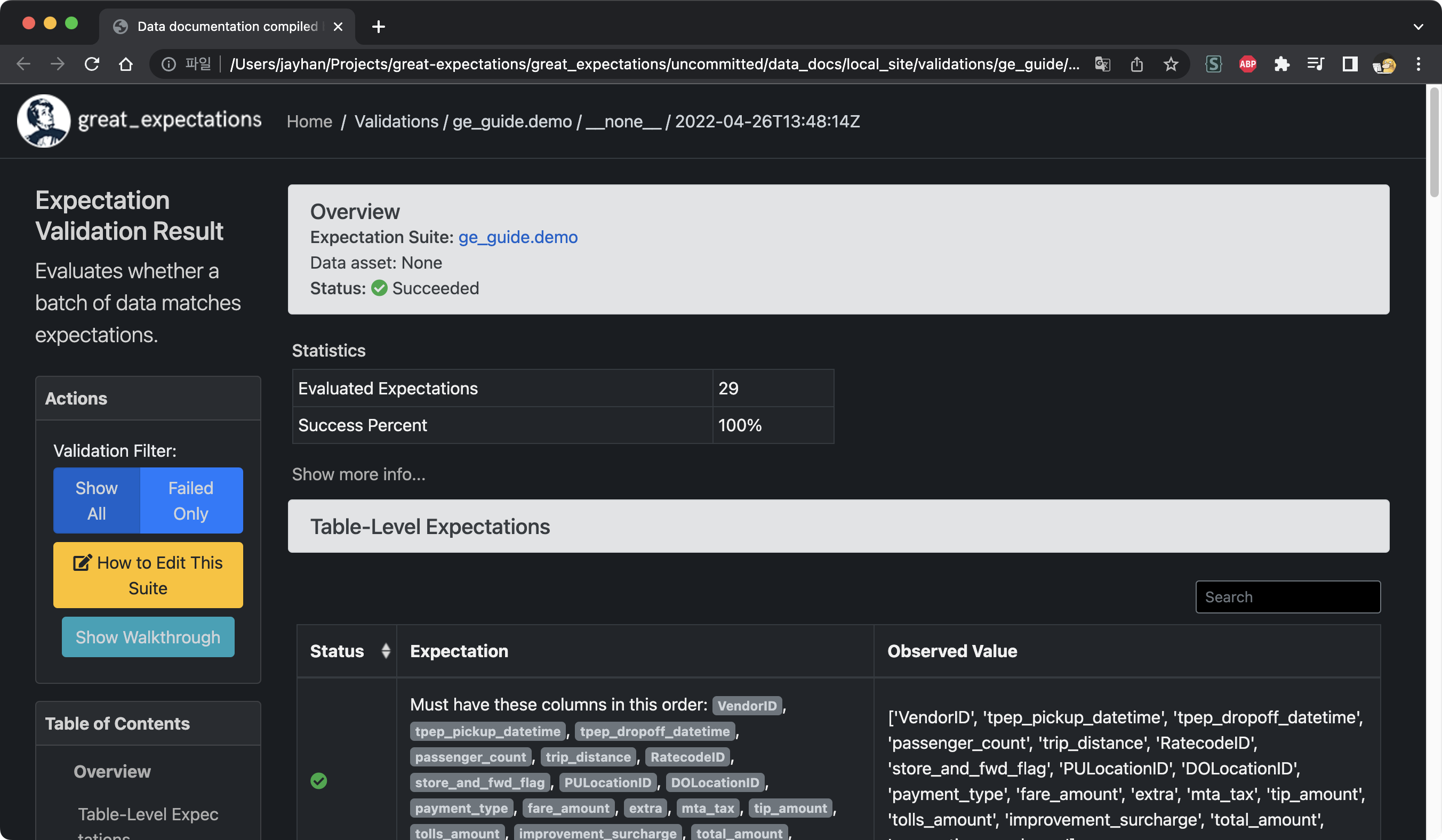
3.3 Expectation Suite 수정
데이터 문서를 살펴보면 여러 Expectation을 다루고 있습니다. 프로파일러를 통해 Expectation을 얻게 되면 기본적으로 다음과 같은 정보들을 얻게 됩니다.
- 컬럼의 데이터 타입
- 최솟값, 최댓값, 평균, 중앙값 등 단순 통계값
- 값의 빈도
NULL값의 개수
하지만 중앙값이 정확히 얼마가 나와야 한다던가, 데이터의 행 갯수가 정확히 몇 개여야 한다던가하는 불필요한 Expectations은 삭제하거나 수정할 필요가 있습니다. Expectation Suite를 수정하기 위해선 다음 명령어를 실행해야 합니다.
1
great_expectations suite edit ge_guide.demo
그러면 Expectation Suite를 어떤 방법으로 수정할건지 물어보는 메시지가 출력됩니다. 1번을 선택합니다.
1
2
3
4
5
6
Using v3 (Batch Request) API
How would you like to edit your Expectation Suite?
1. Manually, without interacting with a sample batch of data (default)
2. Interactively, with a sample batch of data
: 1
그러면 Notebook 파일이 하나 실행되는데 이 파일을 이용해서 Expectation Suite를 수정하면 됩니다. 기존에 존재하는 Expectation들을 삭제하기 위해서는 첫 셀의 내용을 조금 수정해야 합니다.
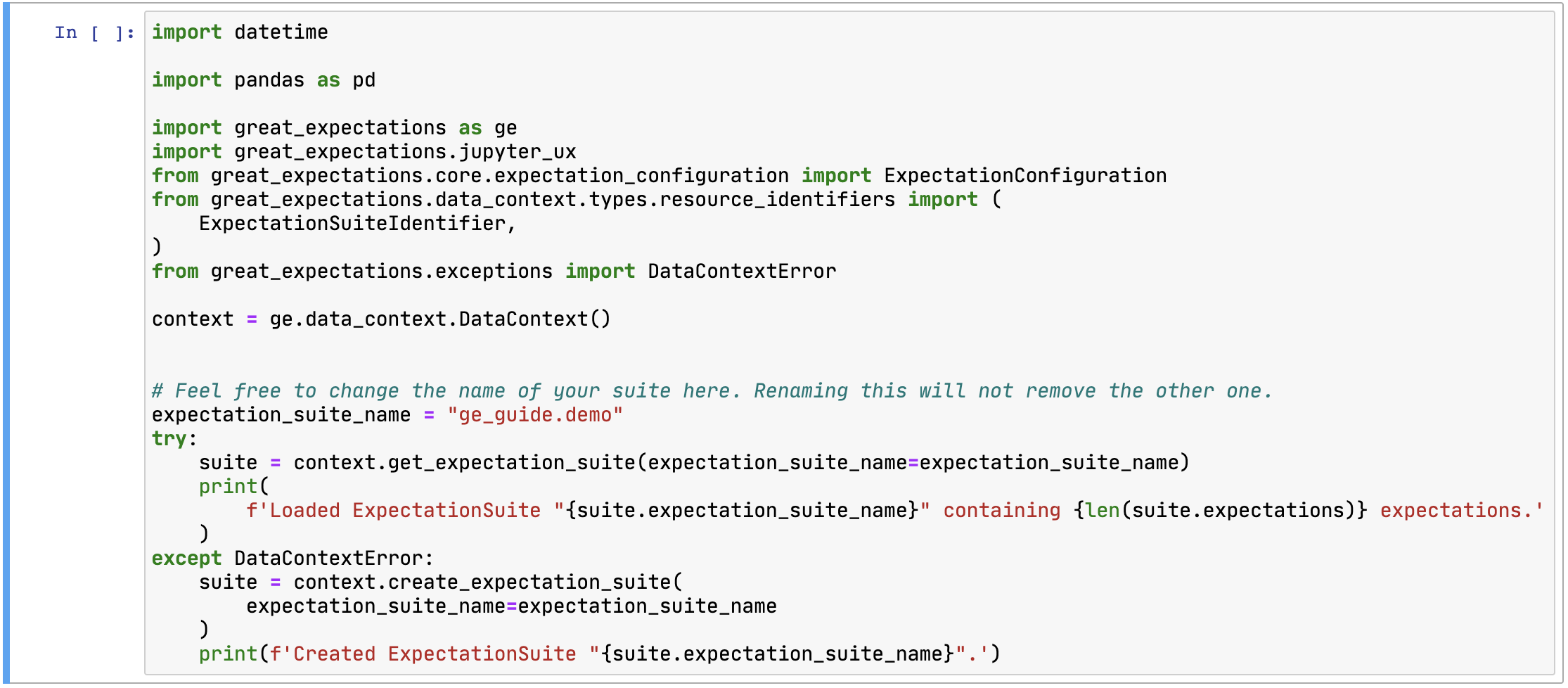
이 셀에서 맨 밑에 있는 try-except 문에서 except 부분만 사용해야 합니다. 그리고 다음과 같이 overwrite_existing=True를 추가합니다.
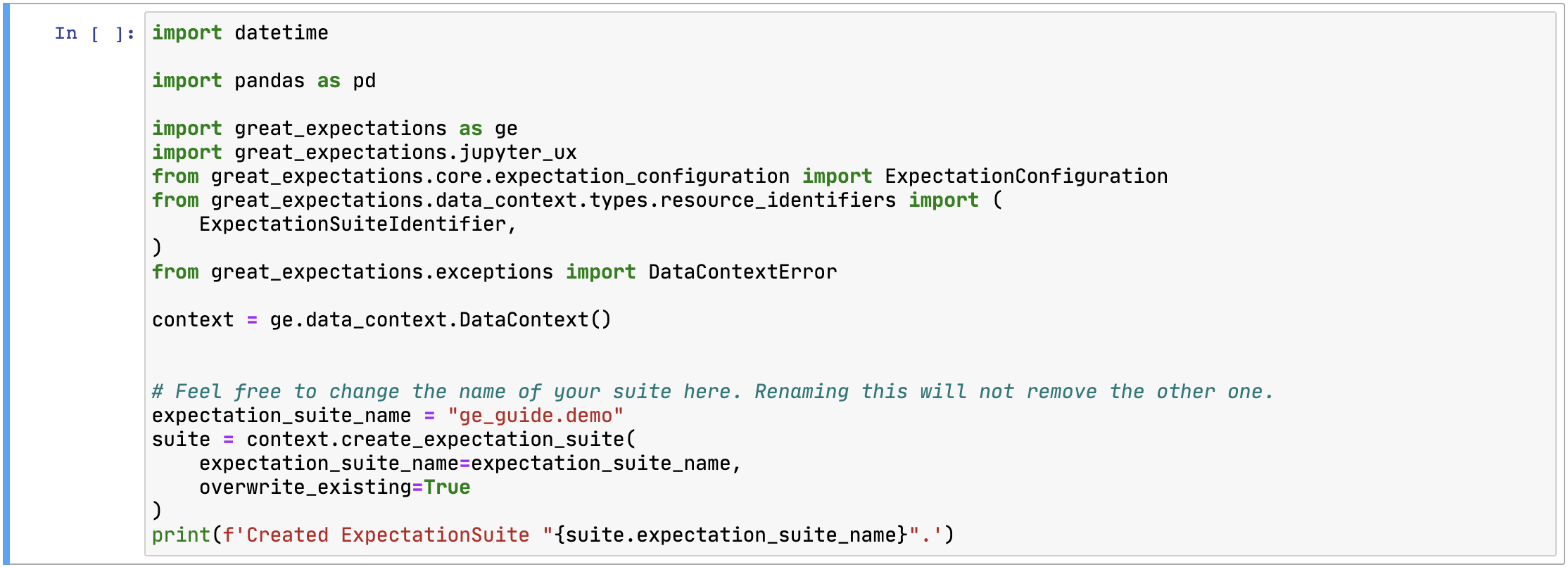
그 이후 필요에 따라서 셀을 추가/수정하거나 삭제하면 됩니다. 저는 다음과 같이 수정해봤습니다.
- 새로운 데이터의 행 갯수가 정해져있지 않기 때문에 Table Expectation에서
expectation_type이expect_table_row_count_to_be_between인 셀을 삭제합니다. - Column Expectation에서
expectation_type이expect_column_mean_to_be_between,expect_column_median_to_be_between,expect_column_quantile_values_to_be_between,expect_column_values_to_be_in_set,expect_column_proportion_of_unique_values_to_be_between인 셀들을 모두 삭제합니다.- 여기서
payment_type컬럼은expect_column_values_to_be_in_set을 남겨둡니다. 범주형 변수에 가깝기 때문입니다.
- 여기서
수정이 끝나면 모든 셀을 처음부터 끝까지 실행해줍니다. 그러면 데이터 문서가 다시 실행되고 올바르게 수정된 것을 확인하실 수 있습니다.
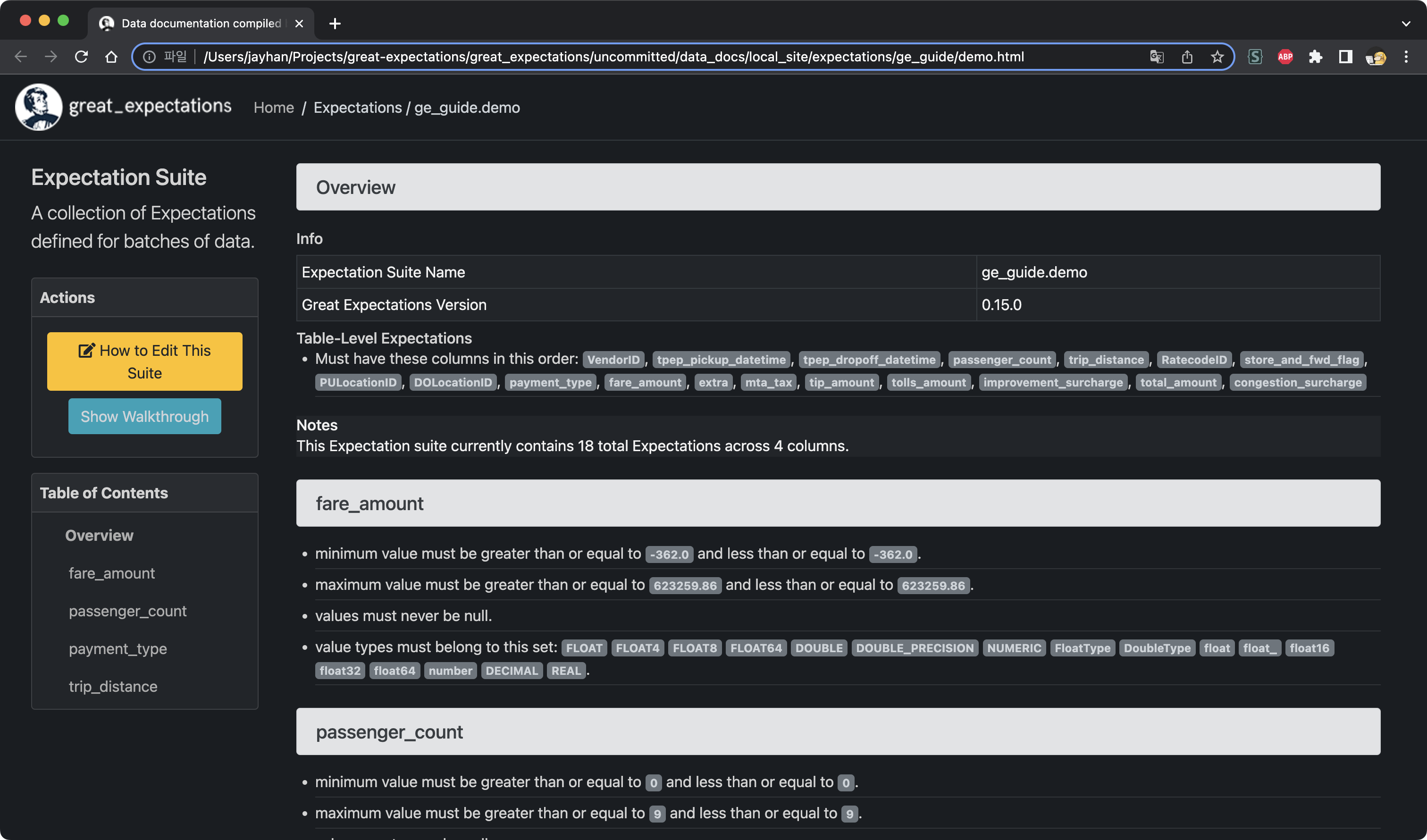
4. 데이터 검증하기
이제 마지막으로 데이터를 검증하는 일만 남았습니다. 여기서는 체크포인트를 사용하는데, 체크포인트는 데이터 배치에 대해 Expectation Suite를 실행하여 검증 결과를 생성하게 됩니다. 우선 터미널에서 아래의 명령어를 통해 체크포인트를 생성합니다.
1
great_expectations checkpoint new ge_guide
그러면 Notebook 파일이 하나 실행됩니다. 여러 개의 셀이 있는데 두 번째 셀을 보면 검증할 데이터에 대한 설정값이 있는 것을 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
my_checkpoint_name = "ge_guide" # This was populated from your CLI command.
yaml_config = f"""
name: {my_checkpoint_name}
config_version: 1.0
class_name: SimpleCheckpoint
run_name_template: "%Y%m%d-%H%M%S-my-run-name-template"
validations:
- batch_request:
datasource_name: NYC Taxi
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_2019-02.csv
data_connector_query:
index: -1
expectation_suite_name: ge_guide.demo
"""
print(yaml_config)
12번 줄을 보시면 data_asset_name이 있는데 기존에 yellow_tripdata_2019-01.csv로 되어 있는 것을 검증 대상 데이터인 yellow_tripdata_2019-02.csv로 수정하면 됩니다. 그리고 맨 마지막 셀의 주석 처리된 내용을 해제합니다. 이제 모든 셀을 실행시키면 데이터에 대한 검증 결과를 얻을 수 있습니다.
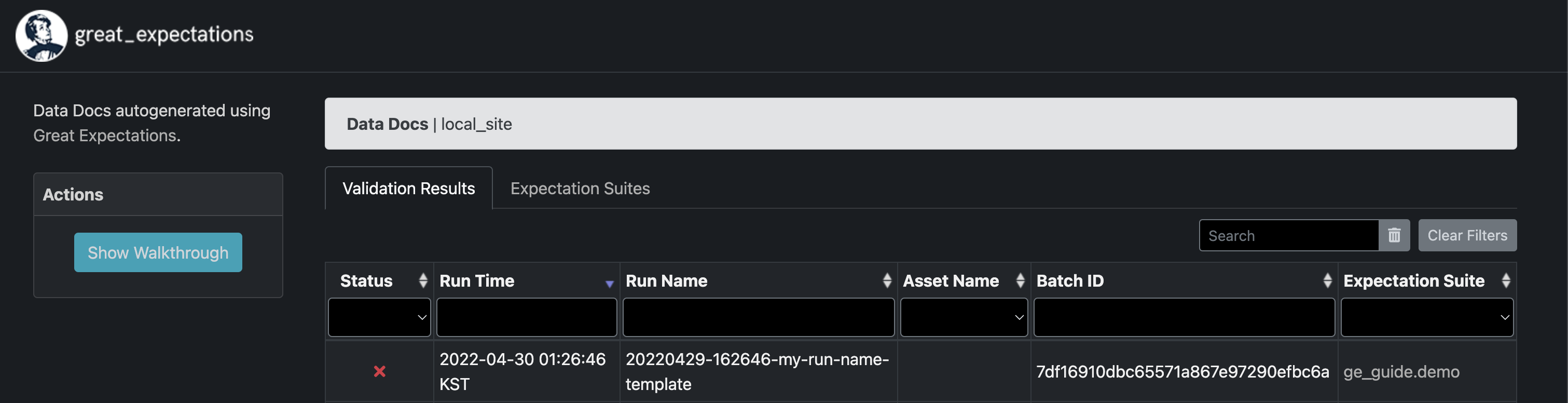
위와 같은 결과 창이 실행되는데 Status에 실패로 표시되어 있는 것을 볼 수 있습니다. 실행 자체는 올바르게 되었지만 데이터에 대한 검증에 실패했다는 의미입니다. 검증 대상이었던 yellow_tripdata_2019-02.csv 데이터에서 예상에 빗나가는 값들이 존재한다는 뜻입니다. 해당 내용을 클릭해보면 평가한 Expectation 수와 그 비율이 나옵니다.
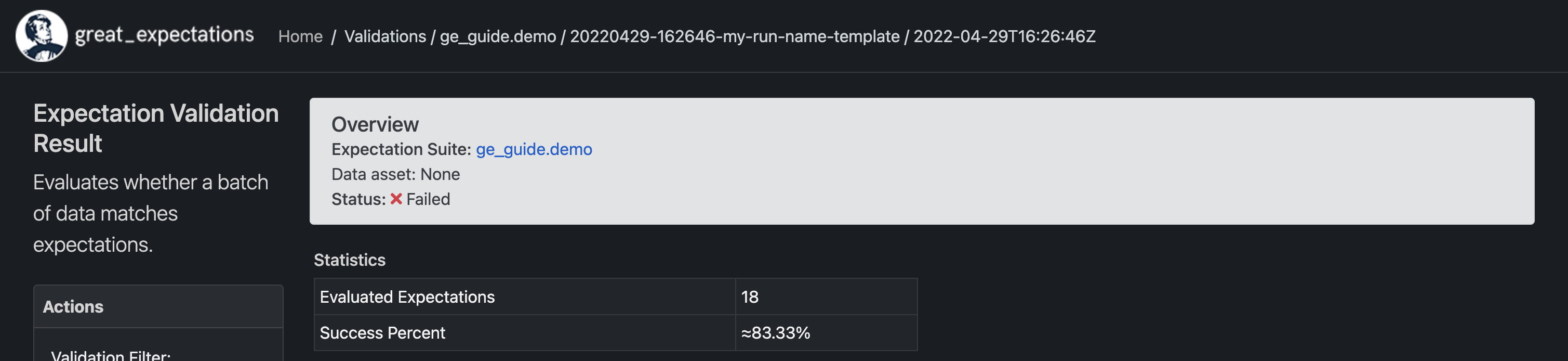
그리고 스크롤을 내리면 일부 컬럼에서 Expectation과 다른 결과로 인해 검증에 실패했다는 내용을 찾을 수 있습니다.
다음 포스트에서는 Crontab을 이용해 스케줄링하는 방법과 외부 프로그램과 통합하는 방법에 대해 알아보도록 하겠습니다.