A worrying Analysis of Recent Neural Recommendation Approaches
Dacrema, Maurizio Ferrari, Paolo Cremonesi, and Dietmar Jannach. “Are we really making much progress? A worrying analysis of recent neural recommendation approaches.” Proceedings of the 13th ACM conference on recommender systems. 2019.

Introduction
최근 몇 년 간 추천 시스템 영역에도 딥러닝 기법들이 두각을 나타내기 시작했습니다. Top-N 추천이나 세션 기반 추천 등 다양한 시나리오의 추천 시스템 연구에서 새로운 기법들이 등장하고 있죠. 하지만 저자는 추천 분야의 발전 정도가 ML의 다른 분야에서 나타나는 발전 정도, 특히 정확도 향상 측면에서 기대만큼 엄청난 수준은 아니라고 지적하고 있습니다.
가령 [1]에서는 신경망 기반의 기법들이 기존의 베이스라인 기법들을 잘 튜닝한 것들보다 유의미한 수준에서 좋은 성능을 보이지 않는다고 꼬집었습니다. 추천 시스템 관점에서도 역시 단순한 Nearest-neighbor 기법들이 신경망 기반의 추천 알고리즘들보다 좋은 성능을 보일 수 있다는 연구도 있습니다. [2]
저자들은 이런 상황이 발생하는 이유를 크게 세 가지로 보았습니다.
- 빈약한 베이스라인 기법
- 새로운 베이스라인으로 성능이 떨어지는 모델 선정
- 연구간 결과를 비교하거나 재현하는 것에 대한 어려움
베이스라인으로 너무 약한 모델을 선정하거나 적절한 파인 튜닝이 이뤄지지 않은 경우도 있으며, 어떤 경우에는 제안하는 알고리즘과 유사한 알고리즘만을 비교하는 경우도 있습니다. 또한 최근 몇 년 간 연구 논문들이 쏟아져 나오면서 SOTA 베이스라인이 무엇인지 추적하는 것도 쉽지 않아졌고요.
뿐만 아니라 연구자들이 너무 다양한 데이터셋, 평가 방법, 평가 메트릭, 데이터 전처리 단계를 사용하는 것도 문제가 될 수 있습니다. 이 점은 소스 코드나 데이터를 공개하지 않은 경우 그 문제가 커질 수 있고요. 마지막으로 최근 응용 ML 분야의 연구 관습도 한 몫을 하고 있습니다. 저자들은 대부분의 연구들을 “게재 가능성”에 초점을 맞추어 진행하면서 이런 문제가 발생할 수 있다고 주장합니다.
저자들은 크게 두 가지 관점에서 이런 문제를 살펴보고 있습니다.
- 재현 가능성 (Reproducibility)
- 최근 연구들이 적당한 노력을 추가하여 재현 가능한가?
- 향상성 (Progress)
- 최신 알고리즘들이 단순하지만 잘 튜닝된 베이스라인 알고리즘과 비교할 때 실제 성능 향상이 이루어지고 있는가?
저자들은 18편의 논문을 선정하였으며 논문 결과를 실제로 수긍 가능한 정도로 재현 가능한 것은 일곱 편에 지나지 않았다고 합니다. 또한 일곱 편 중 여섯 편은 단순하지만 잘 튜닝된 베이스라인 알고리즘보다 높은 성능을 보이지 못했다고 합니다.
Resarch Method
Collecting Reproducible Papers
저자들은 2015년부터 2018년까지 주요 컨퍼런스인 KDD, SIGIR, TheWebConf(WWW), RecSys에 출판된 논문들을 살펴보고 18개의 논문을 다음의 기준으로 선정하였습니다.
- 제안하는 방법이 딥러닝 기반인가?
- Top-N 추천에 초점을 맞추고 있는가?
따라서 그룹 추천이나 세션 기반 추천은 고려하지 않았다고 합니다. 또한 Precision, Recall, MAP과 같은 메트릭이 사용된 논문만 고려하였습니다. Explicit rating과 관련된 연구들은 대부분 MSE, RMSE를 메트릭으로 사용하기 때문에 이런 논문들은 제외되었다고 보면 될 것 같습니다.
이 중에서 재현 가능한 연구들을 추렸으며, 다음의 조건을 만족했을 때 해당 연구가 재현 가능하다고 판단하였습니다.
- 작동하는 소스 코드가 있거나 약간의 수정으로 작동 가능한 소스 코드가 있는 경우
- 논문에서 사용한 데이터셋이 최소 하나 이상 사용 가능한 경우
구현된 소스 코드들 중 많은 디테일이 빠져있는 버전의 소스코드는 재현 불가능하다고 판단하였고, 결국 18개의 논문 중에서 일곱 편만이 재현 가능하다고 판단하였습니다.
Evaluation Methodology
Measurement Method
저자들은 기존 논문에서 사용한 것과 동일한 평가 방법을 적용할 수 있도록 코드를 리팩토링 하였습니다. 특히 학습, 하이퍼파라미터 튜닝, 예측과 관련된 코드는 평가와 분리하였고, 이는 베이스라인 모델에도 동일하게 적용하였습니다. 그리고 재현한 모든 모델들은 논문에서 제시하는 최적의 하이퍼파라미터를 그대로 사용하였습니다.
Baselines
베이스라인 모델들은 개념적으로 단순한 것들을 사용했습니다.
- TopPopular
- 개인화되지 않은 방법으로 모두에게 가장 인기 있는 아이템을 추천합니다.
- ItemKNN
- kNN과 아이템간 유사도를 기반에 둔 가장 전통적인 협업 필터링 방법론입니다.
- 코사인 유사도 $s_{ij}$는 다음과 같이 계산합니다.
- $h$는 상호작용이 적은 아이템의 유사도를 낮추기 위한 shrinkage term으로 사용합니다.
- UserKNN
- 사용자간 유사도를 사용하는 neighborhood-based 기법입니다.
- ItemKNN-CBF
- ItemKNN과 유사하나 아이템의 콘텐트 피처에 대해 계산한 유사도를 사용합니다.
- CBF는 Content-based Filtering을 의미합니다.
- 피처간 유사도는 ItemKNN과 유사합니다.
- ItemKNN-CFCBF
- CF와 CBF를 결합한 하이브리드 알고리즘입니다.
- 유사도를 계산할 때 rating과 피처를 붙인 벡터 $[\mathbf{r}_i, w\mathbf{f}_i]$를 이용합니다.
- $P^3\alpha$
- 사용자와 아이템간 random walk을 사용하는 단순한 그래프 기반 알고리즘입니다.
- 저자들은 낮은 계산 비용 대비 준수한 추천 성능 때문에 본 알고리즘을 추가했다고 합니다.
- $RP^3\beta$
- $P^3\alpha$의 새로운 버전입니다.
위 베이스라인 모델들은 모두 Scikit-optimize를 사용해 최적의 파라미터를 찾도록 하였습니다.
Validation Against Baselines
Collaborative Memory Networks (CMN)
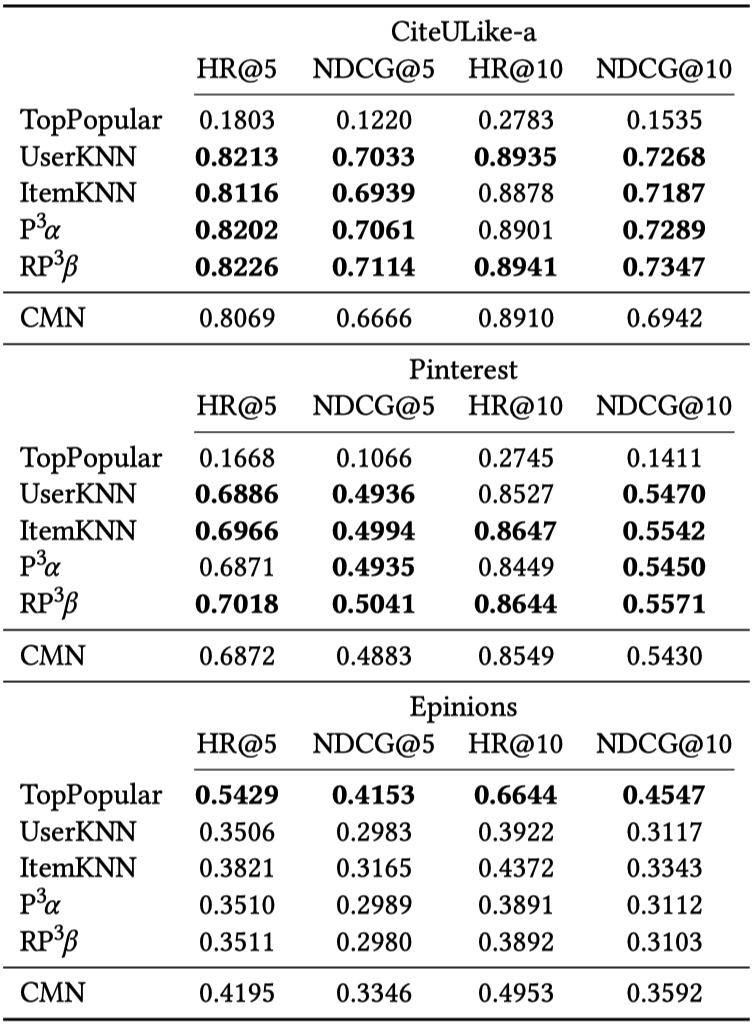
CMN은 메모리 네트워크와 어텐션(attention)을 latent factor 모델과 neighborhood 모델에 결합한 방법입니다. Epinions, CiteULike-a, Pinterest 데이터셋이 사용되었으며, 베이스라인 모델이 어떻게 튜닝되었는지에 대한 정보는 제시되어 있지 않습니다. 모델은 Leave-one-out 과정을 통해 Hit rate와 NDCG로 평가하였습니다.
- 데이터셋 : Epinions, CiteULike-a, Pinterest
- 평가 메트릭 : HR@5, NDCG@5, HR@10, NDCG@10
기존 논문에서 CMN이 모든 베이스라인을 넘어서는 성능을 보인다고 주장한 것에 반해 튜닝된 베이스라인과 비교하여 CMN이 성능이 좋은 경우는 없었습니다.
Metapath based Context for RECommendation (MCRec)
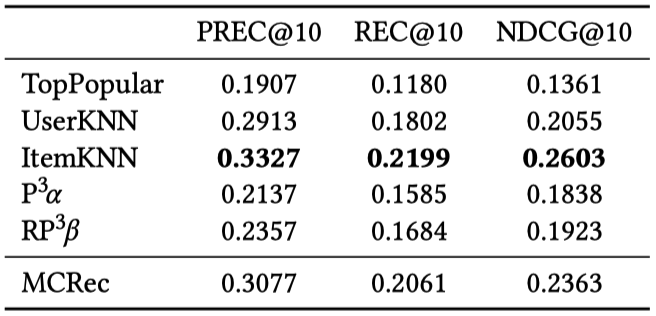
MCRec은 영화 장르 같은 추가 정보를 활용한 메타패스(meta-path) 기반의 모델입니다. 기존 논문에서는 MovieLens100k, LastFM, Yelp 같은 작은 데이터셋에 대해 서로 다른 복잡도의 여러 모델을 벤치마크 하였으며, 해당 데이터셋을 8:2로 임의로 나눠 10회 평가를 수행했습니다. 기존 논문에서 베이스라인으로 사용한 MF와 NeuMF을 제외하고는 하이퍼파라미터 튜닝에 대한 정보는 주어져 있지 않았으며, Precision@10, Recall@10, NDCG@10을 평가 메트릭으로 사용했습니다.
본 논문에서는 메타패스 구현 문제로 MovieLens100k에 대해서만 평가를 진행하였으며, 그 결과 ItemKNN이 가장 좋은 성능을 보이는 것을 확인했습니다. 다른 베이스라인 모델의 경우 MCRec보다 낮은 성능을 보였습니다. 기존 논문에서 MCRec이 가장 좋은 성능을 보인다고 한 것으로 미루어보아 짐작컨대 부적절한 방법으로 테스트 데이터를 나누고 Epoch을 선택한 것으로 생각된다고 합니다.
- 데이터셋 : MovieLens100k
- 평가 메트릭 : Prec@10, Rec@10, NDCG@10
또한 기존 논문의 소스코드를 확인하였을 때 NDCG가 일반적인 방식으로 구현되지 않은 것으로 보아 다른 잠재적인 문제가 있을 것으로 예상된다고 합니다.
Collaborative Variational Autoencoder (CVAE)

CVAE는 콘텐츠와 평점 정보를 모두 활용하는 unsupervised 방식의 기법입니다. 기존 논문에서는 CiteULike 데이터셋을 사용하였고, 베이스라인으로는 당시 최신 딥러닝 기법들을 사용하였습니다. 평가는 Rec@50, Rec@100, Rec@300을 통하여 수행하였고, 학습 데이터와 테스트 데이터는 5회 임의로 나누어 사용했다고 합니다.
- 데이터셋 : CiteULike-a
- 평가 메트릭 : Rec@50, Rec@100, Rec@300
평가를 진행한 결과 짧은 추천 목록에서는 베이스라인 모델들이 CVAE를 상회하는 성능을 보였으며, 추천 목록이 길어질 수록 CVAE가 더 나은 성능을 보였으나 여전히 ItemKNN-CFCBF가 가장 좋은 성능을 보였습니다.
Collaborative Deep Learning (CDL)

CDL은 Stacked Denoising Autoencoder와 CF를 결합한 모델로 콘텐츠 정보와 CF 정보를 결합하여 학습합니다. 전체적인 세팅은 CVAE와 유사하며, 데이터셋 역시 CiteULike를 사용하였습니다.
- 데이터셋 : Dense CiteULike-a
- 평가 메트릭 : Rec@50, Rec@100, Rec@300
평가 결과 대부분의 베이스라인 모델들이 CDL보다 좋은 성능을 보였으며, 또한 CVAE가 CDL보다는 항상 좋은 성능을 보이는 것을 확인하였습니다.
Neural Collaborative Filtering (NCF)

NCF는 MF를 신경망을 사용한 내적으로 대체한 방법론으로 논문에서 제안하는 NeuMF 방법론은 MovieLens1M과 Pinterest 데이터를 사용해 평가하였습니다. 평가 시에는 Leave-one-out을 사용하였고 분리된 학습 데이터와 검증 데이터는 공개가 되어 있습니다. 평가는 Hit Rate와 NDCG를 이용하여 수행되었습니다.
공개되어 있는 소스 코드에 Epoch이 설정되어 있는데 테스트 데이터를 사용해 튜닝된 값으로 본 논문에서는 검증 데이터를 이용해 올바른 방법으로 재설정하였다고 되어 있습니다.
- 데이터셋 : Pinterest, MovieLens 1M
- 평가 메트릭 : HR@5, NDCG@5, HR@10, NDCG@10
평가 결과 Pinterest 데이터에 대해서는 베이스라인 모델들의 성능이 더 좋았고, MovieLens 1M에 대해서는 NeuMF의 성능이 가장 좋았습니다. 저자는 여기에 Scikit-learn에 있는 Elastic Net을 사용해 추가 평가를 진행하였는데 해당 모델의 성능이 가장 좋았다고 합니다. (위 이미지 중 SLIM)
Spectal Collaborative Filtering (SpectralCF)
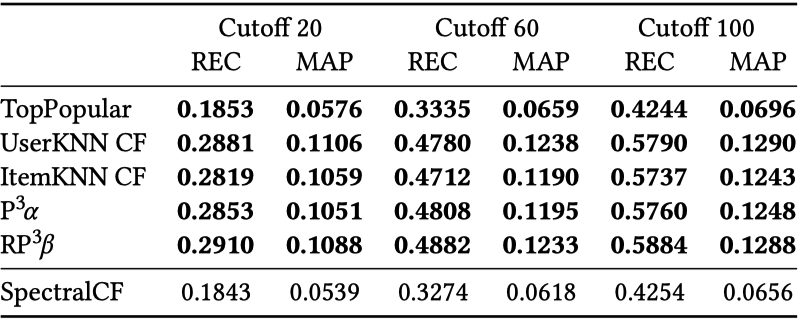
SpectralCF는 Spectral Graph Theory를 이용해 cold-start 문제를 해결하기 위해 설계되었습니다. 사용자-아이템 관계 그래프를 bipartite 형태로 설계하여 새로운 컨볼루션 연산을 통해 추천을 제공하는 알고리즘입니다. 기존 논문에서는 MovieLens 1M, HetRec, Amazon Instant Video 데이터셋을 사용해 평가를 하였고, 최신 신경망 기반의 추천 알고리즘을 포함해 여러 알고리즘과 비교 분석하였습니다. 평가는 8:2로 데이터를 나누고 Recall과 MAP를 이용하였습니다.

저자는 해당 논문을 분석하던 중 MovieLens 데이터에 대해 SpectralCF가 매우 큰 폭으로 높은 성능을 보이는 것을 확인하고 학습 데이터와 테스트 데이터를 탐색한 결과 무작위 샘플링으로 얻을 수 없는 분포 차이를 확인할 수 있었다고 합니다. 그래서 기존 논문의 방법이 아닌 자체적인 데이터 분할을 통해 하이퍼파라미터를 최적화했다고 합니다.
- 데이터셋 : MovieLens 1M
- 평가 메트릭 : Rec@20, MAP@20, Rec@60, MAP@60, Rec@100, MAP@100
그 결과 모든 베이스라인 모델들이 SpectralCF보다 좋은 성능을 보이는 것을 확인하였습니다.
Variational Autoencoders for Collaborative Filtering (Mult-VAE)

Mult-VAE는 Variational Autoencoder에 기반을 둔 implicit feedback을 위한 협업 필터링 기법입니다. 기존 논문에서는 MovieLens 20M, Netflix, Milion Song 데이터셋을 사용하여 평가를 수행하였습니다. 저자는 Mult-VAE가 베이스라인 모델보다 일관되게 좋은 성능을 보이는 유일한 모델이었으며, 10%~20% 정도 더 좋은 성능을 보였다고 합니다. 또한 위에서 사용했던 ElasticNet을 이용한 SLIM 모델보다도 최대 5% 더 높은 성능을 확인할 수 있었다고 합니다.

Recall과 NDCG를 다른 컷오프에 대해서도 실험하였을 때는 SLIM이 더 나은 성능을 보이는 경우도 있었습니다. 따라서 위처럼 신경망 기반의 추천 모델이 더 좋은 성능을 보이더라도 부분적이거나 평가 지표 선택에 의존적일 수 있다고 할 수 있습니다.
Discussion
Reproducibility and Scalability
재현 가능한 모델들에 대해서 실험을 진행한 결과 대부분의 모델들이 재현이 불가능하거나, 논문에서 제시하는 내용과는 다른 결과를 보여주었습니다. 저자는 이에 대해 제안된 방법론들의 계산 복잡성을 문제로 제시합니다.
과거에 사용한 넷플릭스 데이터는 1억 개의 평점으로 구성되어 있는 반면, 요즘 많이 사용하는 데이터들은 고작 수십만 개에서 수백만 개의 평점을 갖고 있습니다. 과거였다면 데이터가 너무 작다고 여겨졌겠지만 요즘은 하이퍼파라미터 최적화를 위해 매우 많은 시간을 할애해야 할 만큼 모델이 많이 복잡해졌습니다. 물론 본 논문에서 제시하는 nearest-neighbor 방법론들은 확장 가능성에 대한 문제가 발생할 수도 있지만 적절한 데이터 전처리와 샘플링으로 그 문제를 해결할 수 있을 것으로 생각한다고 합니다.
Progress Assessment
하지만 이런 복잡한 모델이라도 본 논문을 통해 베이스라인 모델이 더 높은 성능을 보이는 것을 확인하였습니다. 논문에서는 문제의 원인을 베이스라인 선정과 해당 베이스라인에 대한 빈약한 최적화로 꼽고 있습니다. 또한 최근 많은 논문들이 NCF를 SOTA 베이스라인으로 선정하고 있는데, 위에서 본 것처럼 한 가지 데이터셋에 대해서만 좋은 성능을 내기 때문에 적절한 베이스라인이 아니라고 주장하고 있습니다.
또 다른 원인으로는 논문마다 사용하는 데이터셋, 평가 방법이 너무 다양해 일관성이 없다는 점을 꼽았습니다. 대부분의 평가에 주 요소들이 논문을 정당화하는 용도로만 선정된다는 이야기인데요. 물론 평가 메트릭의 경우 도메인에 따라 달라질 수 있다는 이야기도 하고 있습니다.